
RAGで実現!生成AIと社内データが連携し質問に回答

※この記事は、2024年4月開催の当社オンラインセミナーの内容を元に再構成したものです。
人工知能(AI)や生成AIの開発を手掛ける木村情報技術では、生成AIに関するさまざまなお客様の支援を行っていますが、多くの企業が「社内に存在する膨大なデータを活用して、生成AIに質問に答えさせるにはどうすれば良いか?」という課題に直面しています。
しかし現実的には、自社専用のLLM(Large language Models/大規模言語モデル)の構築や、社内の情報やデータを直接生成AIに学習させることは困難です。
そこでこの記事では、そうした課題解決に向け注目されている「RAG(Retrieval Augmented Generation)」について、その仕組みと具体例をご紹介します。
1.RAGの概要と仕組み
RAGは日本語で「検索拡張生成」とも呼ばれ、その仕組みを一言で言うと「カンニングさせる」ことです。
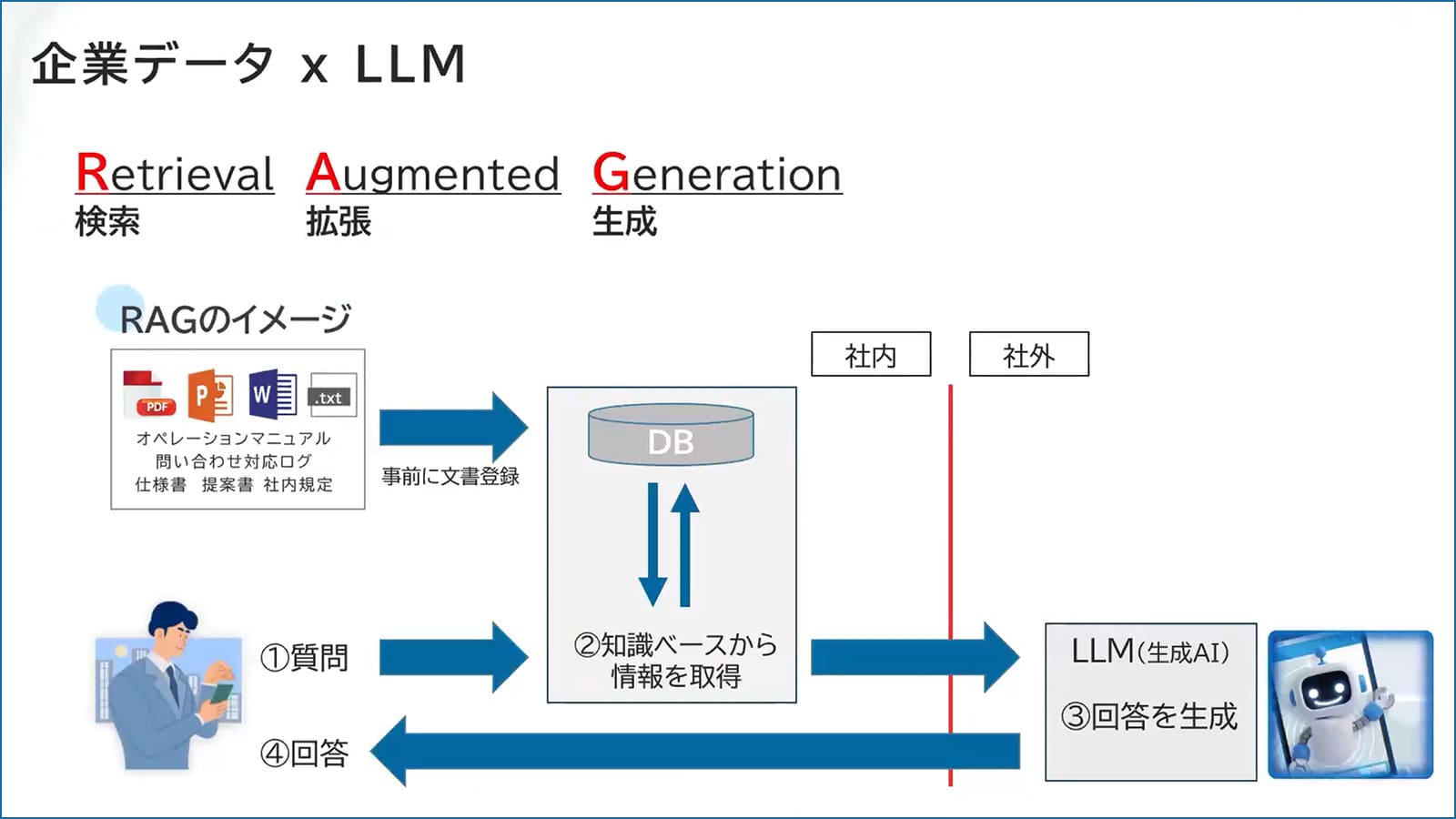
RAGの概要
例えば「東京スカイツリーの高さは何メートルですか?」と質問したいとします。
この場合、データベース(DB)にあらかじめ「東京スカイツリーの高さは634メートルです」という情報を入れておくと、さきほどの図の流れで回答が得られます。
- 質問する。
- 質問に関する情報が知識ベース(DB)から取得される。
- 取得した情報を挿入した質問が、生成AIに投げかけられる。
(この場合「東京スカイツリーの高さは634メートルですが、東京スカイツリーの高さは何メートルですか?」となります。答えを挿入した質問が投げかけられており、いわゆるカンニング状態です。) - 生成AIが回答する
社内の様々なマニュアルや規程集といった情報・文書ファイルを取り込むと、それをGPTが使いやすい形に整えます。こうすることで、質問すると検索が実行され、ピックアップされた情報がLLMに渡され、最終的な回答が生成されます。
2.RAGを使った社内データ検索の実例
当社で活用しているRAGを用いて、社内データを検索した実例をご紹介します。下図のように、システムの枠内にPowerPointやWord、PDFなどのファイルを直接ドラッグ&ドロップするだけで、簡単にデータが取り込めます。
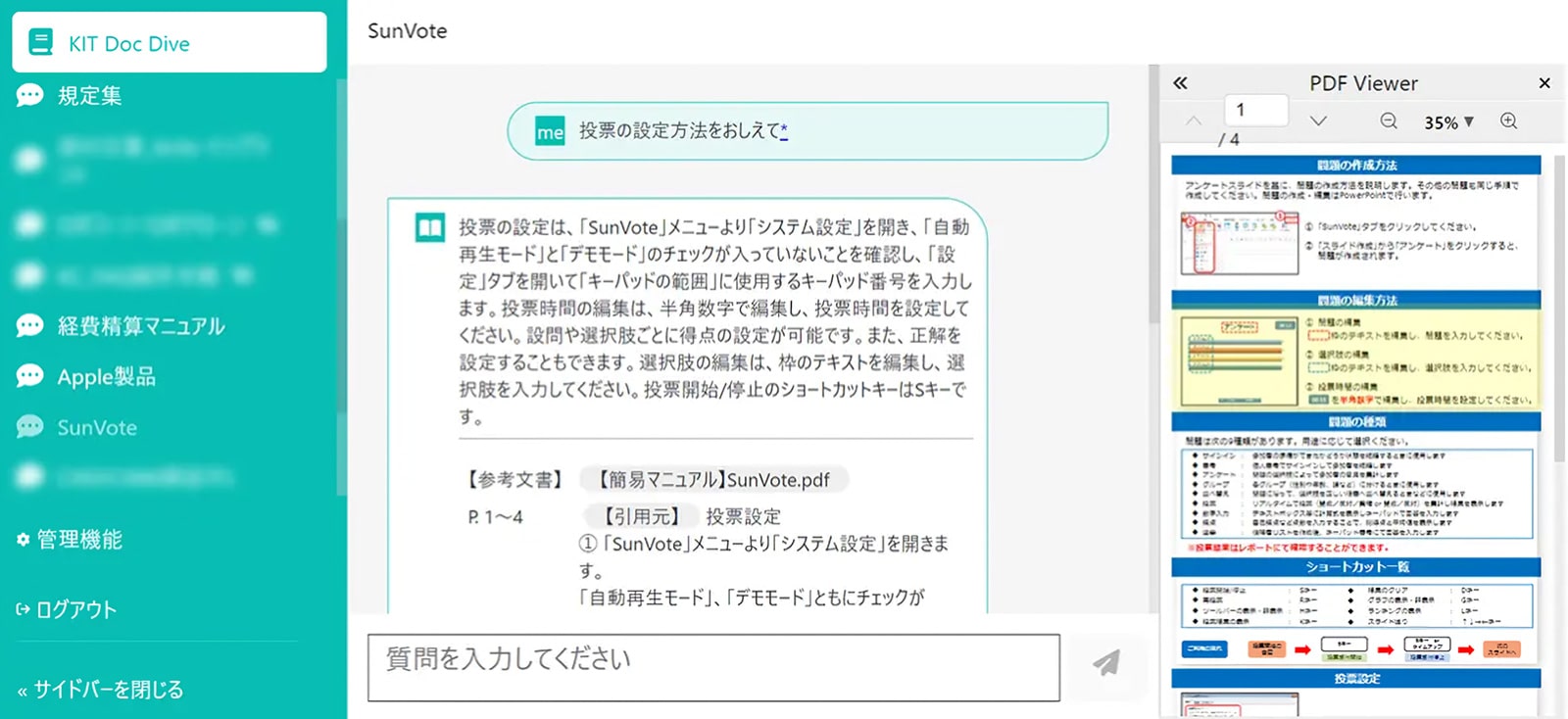
データをアップロードすると、内部では生成AIが自動的にデータベースを作成します。当社が取り組んでいるデータの構造化のポイントは、「FAQ形式にすること」です。
FAQ形式は構造化の1つの方法であり、これだけが唯一の方法ではありません。
しかし、さまざまな検証結果と、これまでAIチャットボットの研究・開発を行ってきた経験から、回答精度の向上と安定した品質の実現のためには、現時点ではこの方法が最適と判断しました。
(1)社内の情報について質問してみる
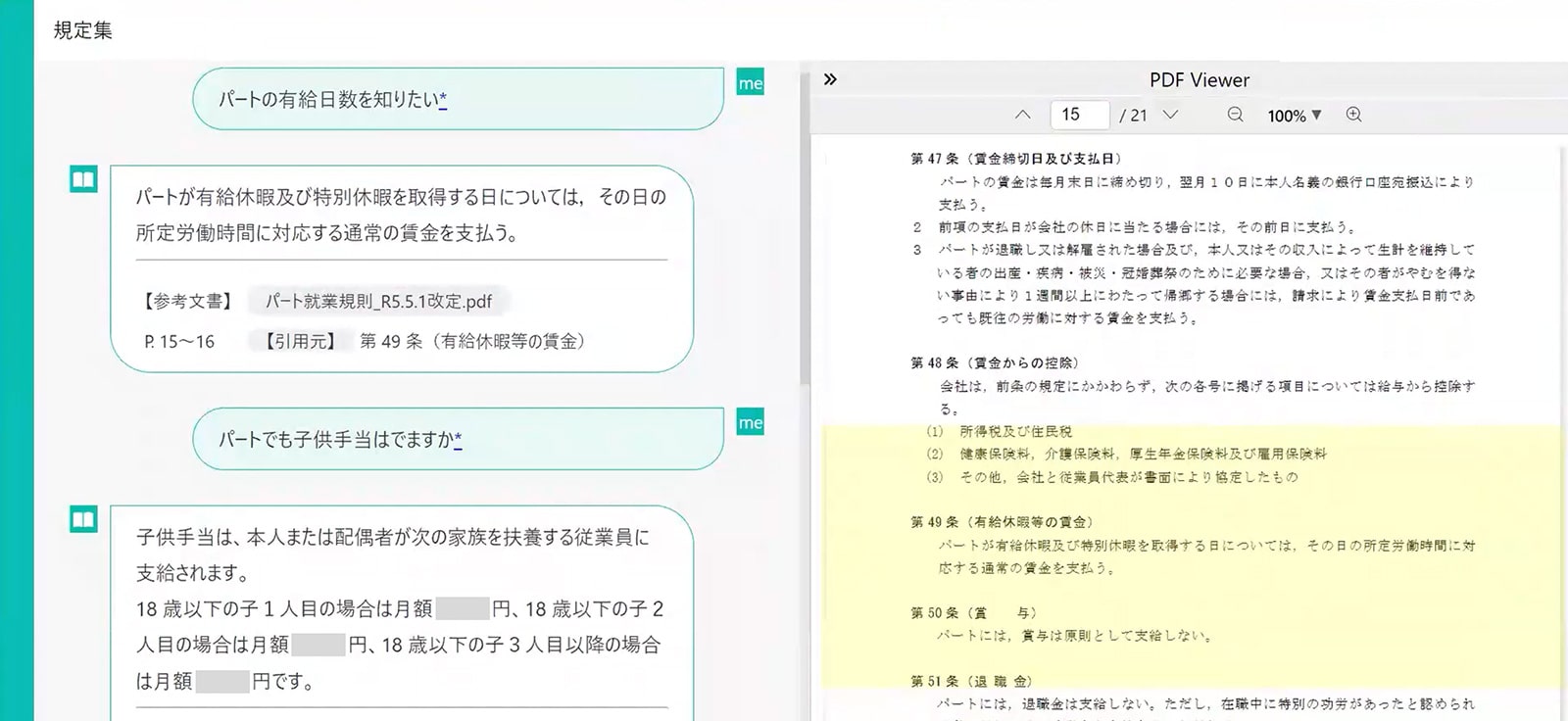
それでは実際に、事前に当社の社内規程を取り込んだ生成AIに質問してみます。
例えば「パートの有休日数を知りたい」と質問すると、生成AIは回答とその根拠となる資料を提示してくれます。加えて、どの資料の何ページにその情報が書かれているかまで教えてくれて、ビューワーには該当箇所が黄色でハイライト表示されます。
(2)RAGの便利さと課題
このようにRAGは非常に便利ですが、生成AIそのものが抱える課題には注意が必要です。特にハルシネーションと呼ばれる、生成AIが誤った回答をする現象には気を付ける必要があります。
例えば下図のように「半休の取り方は?」と質問した場合、「午後休は午後1時から午後6時までです」と回答がかえってきていますが、最初は「午後1時から午後5時までです」とかえってきていました。
これは、LLMが持っている情報では終業時間が午後5時までの会社が多かったため、誤った回答が出力されたものです。データ自体がFAQ形式で構造化されていても、その情報が誤っている場合があります。

一方で、当社は長年のAIチャットボットなどの研究開発の経験から、回答の正確性にこだわった仕組みを採用しており、生成AIが適当に応えるわけではありません。
例えば、生成AIの学習データが社内規程のみの場合、上の図のように「Zoomの使い方が分からない」と質問しても、「情報が不足しているため回答できません」と回答されます。
(3)データベースのチューニング
生成AIが誤った情報を出力した場合は、内部のデータベースに誤ったデータが含まれている可能性があります。このデータベースを直接修正・編集することで、誤った情報を訂正することができます。
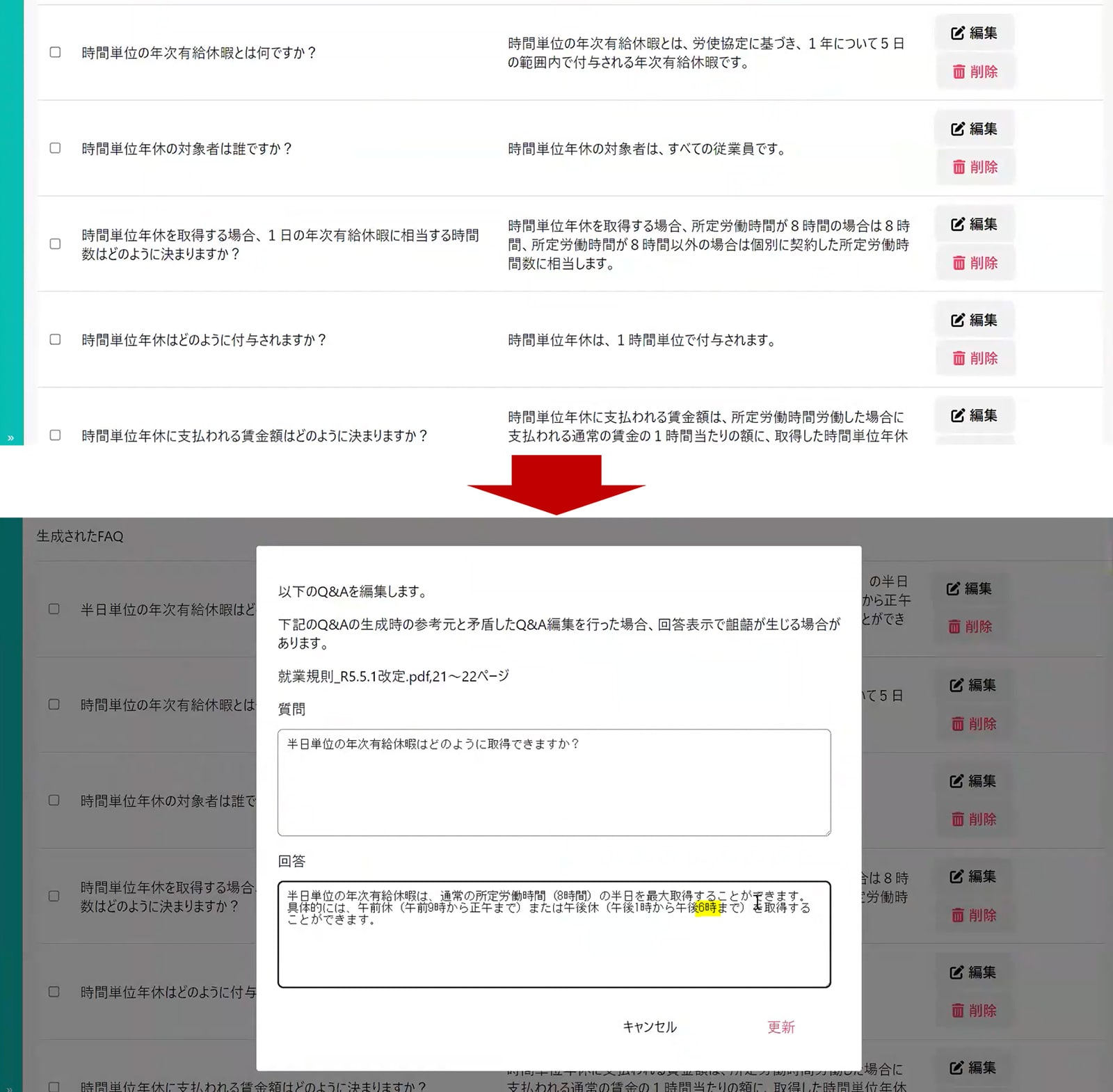
5時を6時に修正する
このように、RAGの仕組みでは、データベース自体がFAQ形式になっており、さらに修正や編集、管理が可能です。このような機能を備えたシステムは、他にはあまり例がありません。
当社は、これまでAIチャットボットの開発などで培った、回答品質の向上や、利用者に分かりやすい情報の表示方法などにこだわってサービスを開発してきました。その経験から、このような管理機能は必須だと考え実装しています。

3.よくある質問
最後に、GPTや生成AIについて、当社によく寄せられる質問とその回答をご紹介します。
Q1:RAGの環境や生成AIを使ったシステムに関するセキュリティはどうなっていますか?投入したデータが生成AIに学習されることはありませんか?
A1:当社のプラットフォームでは、APIの仕組みを利用しており、利用規約に基づき、読み込ませたデータは学習されません。
また、プラットフォームはAzureやAWSなどの仮想的な閉鎖環境で稼働しており、情報漏洩の防止に万全のセキュリティ対策を講じています。
多くの企業でも同様に、OpenAIのGPTを直接導入するのではなく、AzureのGPTなど、セキュリティ基準を満たしたクラウド環境を選択しています。
さらに、AWS上などに企業ごとの専用環境を構築し、他社がアクセスできないように厳重に管理することも可能です。
Q2:GPT以外にもClaudeなどの生成AIがありますが、どのエンジンを選べばいいのでしょうか?
A2:現在、多くの場合でGPT-3.5とGPT-4.0が選択式になっています。またClaudeやGeminiなども登場しており、APIを切り替えることでそれぞれの生成AIの特徴を活かせる仕組みにしたいと考えています。
Q3:OpenAIのGPTとAzureのGPTでは、回答に違いはありますか?同じバージョン同士なら、同じ回答が得られるのでしょうか?
A3:この点について、OpenAIとMicrosoftが公式に明らかにしているわけではありませんが、Microsoftは独自にチェックを行っている可能性があります。OpenAIでは回答が返ってくるけれど、Microsoftでは返ってこない、というケースが複数見られました。
生成AI活用システム構築サービス「プライベート生成AI Powered by GPT」
この記事では、「プライベート生成AI」シリーズの中から、企業内データ検索×生成AI「KIT Doc Dive」を活用した事例をご紹介しました。
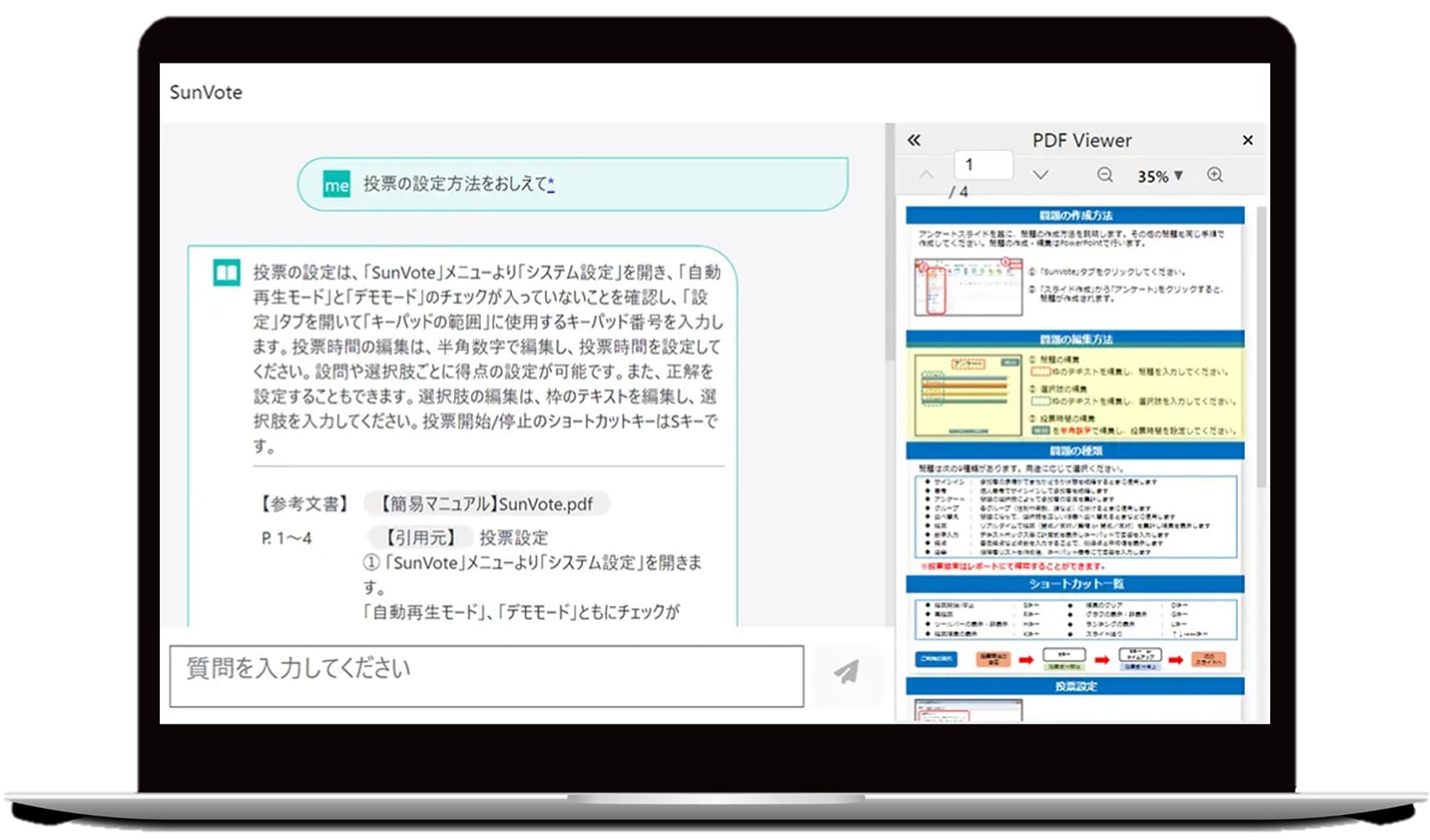
企業内データ検索×生成AI「KIT Doc Dive」
特長1:文書ファイルをアップロードするだけ
複数の異なる形式(Word、PDF、PowerPointなど)の文書ファイルをまとめてアップロードできます。事前準備はこれだけです。
特長2:探したい情報を質問するだけ
回答とあわせて、対象の文書ファイルと引用元の情報が表示されます。さらにPDFViewerで該当箇所が自動表示され引用元がハイライトされます。






