
ChatGPTとRAGでナレッジツールの簡単構築事例

従来のAIは質問と回答を事前に準備するというのが一般的でした。これは非常に手間がかかるため、プロジェクトが回りづらいというのが大きな課題でしたが、間違えてはいけない情報に正確に対応することは得意です。AIの質問数と回答数は無限ではなく、基本的に上限があります。
生成AIの普及により、その手間や上限を大幅に改善することが出来るようになっています。特に独自の情報を学習させる手間が大きく削減できるようになってきていることがポイントです。ただし、生成AIも万能ではありません。
生成AIの課題

ChatGPTが有名ですが、生成AIはインターネットで取得したことは大抵答えられます。しかし、組織独自の情報には答えられません。これまで組織独自の情報を生成AIに回答させることが大きな課題でした。その他にも最新情報に弱いという弱点があります。大規模言語モデルにRAG(検索拡張生成)を組み合わせることで、それらの課題を解決することができます。
RAG(検索拡張生成)とは
生成AI界隈ではRAG(検索拡張生成)が注目されて盛り上がっています。これは文書群やDB等から知識ベースを構築しておくことで、生成AIの知識を補完する手法です。
生成AIそのものを強化することも可能ではありますが、莫大な費用がかかります。RAGは知識を補完する手法なので生成AIの強化と比較するとイニシャルコストを大きく抑えることができます。
生成AIのライフサイクルは短いです。3年後に同じ生成AIを使っている可能性は極めて低いでしょう。そのため生成AIそのものを強化することはお勧めできず、RAGが有力な強化方法となります。
独自の情報に回答するチャットボットを構築する場合、RAGを駆使すれば文書を投入するという最低限の追加コストで済みます。回答を返す機能と知識ベースを抽出する機能を分けておくことで生成AIの世代交代や別の生成AIへの乗り換えも柔軟に対応できるというメリットもあります。
他にも生成AIを強化する手法がいくつかありますが、今回はRAGに焦点を当てました。特に組織独自の情報について答えるナレッジツールをご検討の場合はRAGを検討していただくと良いかと思います。

生成AIとRAG(検索拡張生成)の構築事例
例えば当社開発のKIT Doc DiveはChatGPTをエンジンとして扱っていますが、様々な文書やDBをデータストアに投入することができます。これにより共有サーバー等に保存されている議事録や資料などをベクトルデータに変換し知識ベースとします。そして、学習データは外部の方に2次利用されることはありませんのでご安心ください。ビジネスにおいて機密情報が守られているというのは非常に重要なことです。

ユーザーからの質問に対して、アプリケーションは知識ベースを見に行きます。知識ベースの根拠をChatGPTにパスしてユーザーへ正確な回答を返します。当社では証拠となる文書の該当箇所をハイライトして表示する機能も実現しました。これはRAG(検索拡張生成)という手法のモデルケースです。
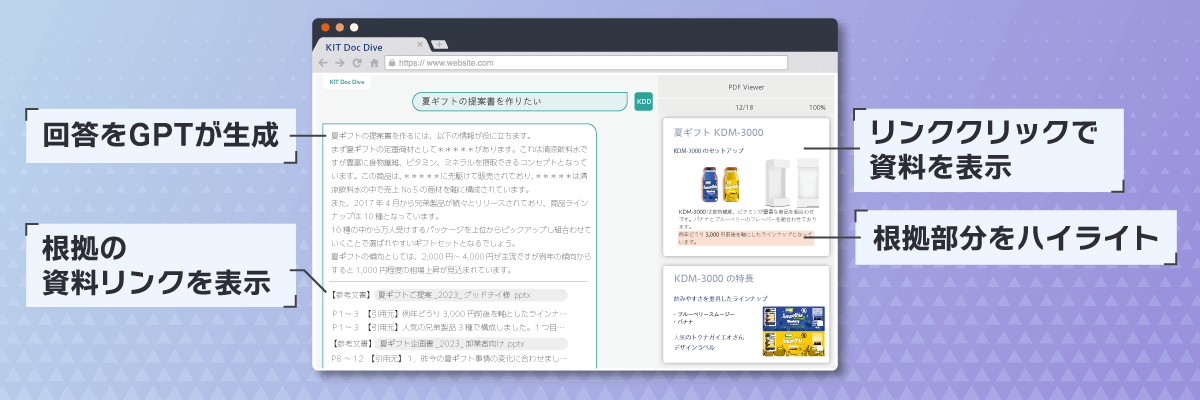
当社では社内の文書を投入し、ナレッジツールとして扱えるように開発しています。導入いただいている企業様にも社内の機密文書を投入いただいて活用いただいています。
提案書、社内規定、調査資料、研修文書などをナレッジとするのが基本的な使い方になります。調べたいことをユーザーが入力すると回答、根拠を表示します。
従来からある文書検索ツールは文書を探すことが目的となりますが、KIT Doc DiveはRAGにより文書から生成AIが根拠をもとに回答を生成する一歩進んだケースとなっています。
この他にも生成AIの活用についてご興味があればご紹介させていただきます。
生成AI活用ケース一覧
- 営業ロールプレイの相手として
- 音声認識から議事録や申込書などのフォーマット化
- 問い合わせログのタスク振り分けと感情分析
- レポートの採点を定性的評価
- 文書を要約
- 配送データから配送ルートの作成
- 社内文書からナレッジ生成、チャットボット構築
- DBやDWH用のSQL作成
当社ではChatGPTはもちろん、Amazon BedrockのClaudeなども研究開発を進めております。有名なエンジンであれば良いというものでもありませんので、詳細にご興味のある方はぜひお問い合わせください。




