
ニューヨークタイムズとOpenAI

著作権とフェアユースのあり方について世界が揺れています。商売のために執筆している記事や画像までも生成系AIが取り込み転用している、それが2023年8月現在における生成系AIの本質です。
ニューヨークタイムズはOpenAIに法的措置を実施するかを検討中とのことです。詳細は係争に関わるためコメントはありません。何が問題なのか、勝敗により何が起こるのかのシナリオを予想していきます。あくまで1つの予想ですので、ご参考までにお願いします。
何が問題なのか
著作物を流用する場合は著作者の許可を得る必要がある、という前提があります。しかし何もかも許可を得なければならないとなると公共の利益に反してしまいます。そのため米国などでは一定の条件付きで流用が認められています。一方、日本ではフェアユースを明文化していないため個々の事例によって判断がなされており、米国に比べると比較的緩い状態です。
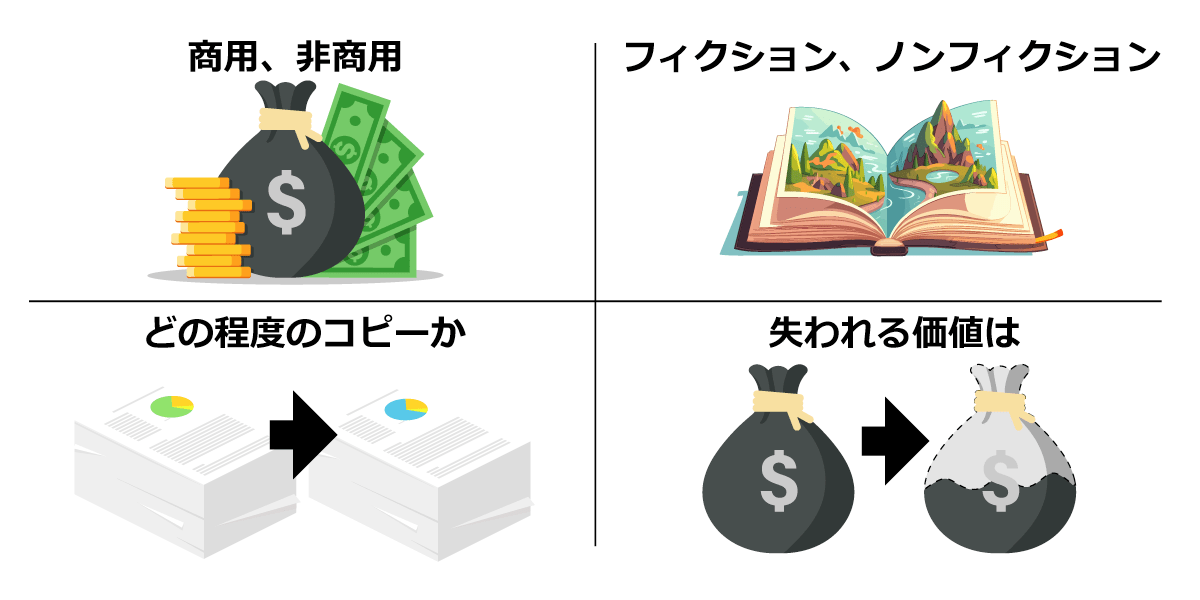
フェアユースのポイント
- 商用、非商用
- フィクションノンフィクション
- どの程度のコピーなのか
- それがあることで失われる価値
ニューヨークタイムズの件を紐解く
ニューヨークタイムズの記事をOpenAIが学習しアウトプットした、という点が非常に問題になります。ニューヨークタイムズにとって記事は生命線です。それをAIに学習されほぼ完全なコピーとして扱われていました。それだけでも問題ですが、そのコピーにより失われる価値はとても大きいものです。
ChatGPTのような生成系AIはインターネット上のデータを収集し、データマイニングを行っています。それはほとんどの場合、著作者の許可を得ていません。
ここでAIによる出力がフェアユースに該当するかという論争があります。ChatGPTは新聞記者の文章をほぼそのまま転用します。これにより、オリジナル記事の価値損失が発生するためフェアユースの適用外と考えられます。その価値損失について係争が行われようとしている、そういう状況にあります。
OpenAIが勝ったら
AIによる学習と出力はフェアユースであると認められる可能性があります。100%同じものは出力していない、商用の競合にはなり得ない、という観点からです。
その場合、多くのコンテンツサイトにおいてAIのためのスクレイピングのブロックが行われることになりそうです。
OpenAIが負けたら
OpenAIが負けた場合、超多額の罰金が科せられることになります。それだけでも致命傷ですが、Microsoftの後ろ盾により耐えれる可能性はあります。
また、著作権侵害を行った場合の複製物について裁判所は破棄の命令を出すことが出来ます。これはMicrosoftの後ろ盾が無くなる理由になり得ます。OpenAIにとっての最悪のシナリオがこちらになるでしょう。
裁判所は学習データの破棄を命令するか

著作権侵害が認められた場合、裁判所は複製物の破棄を命令することが可能です。大規模言語モデルの特性上、一部だけを取り除くことは極めて困難であるため全てのデータ破棄を求められるでしょう。
複製物の破棄とはChatGPTの学習データそのものであり、莫大な開発費用を投じて調整してきた学習データの破棄を行うとChatGPTはサービスの停止に等しい状態になってしまいます。
他の生成系AIへの影響
OpenAIが負けた場合はStable Diffusion、ChatGPT、などインターネット上のデータを集めたAIは軒並み再スタートを強いられることになります。これらのAIはシャドウライブラリと呼ばれている海賊版サイトを学習していることもあります。海賊版サイトと同様のリスクを抱えることはAI開発企業にとって訴訟リスクを伴うため非常に脅威です。
MicrosoftがOpenAIの後ろ盾になる理由

Microsoftはブラウザシェア、検索シェアなどで辛酸をなめさせられてきました。その起死回生の一手がOpenAIの持つChatGPTだと言われています。私自身もChatGPTを使うことがありますが、素晴らしいAIです。
Microsoftのブラウザシェアと検索エンジンシェアを回復させ、テックビジネスを取り戻すための特大パンチ、それがChatGPTなのです。事実、Bingの検索シェアは急激に増加しており2023年8月時点では10人に1人程度はBingを使っています。もし学習データの破棄が行われれば、Microsoftにおいて戦略の再検討が行われることが予想されます。
ニューヨークタイムズとOpenAIのまとめ
OpenAIが敗北すると生成AIの進化が足踏みし構築の見直しを行うことになりそうです。OpenAIが勝利すると著作をビジネスにしてきた企業にとっては何かしらの防御策を講じることになります。ChatGPTは素晴らしいAIであることは間違いないですが、今後の動向から目が離せません。




